
쓰레드의 등장배경
멀티 프로세스 기반의 단점은 다음과 같다
프로세스 생성이라는 부담스러운 작업과정을 거친다
두 프로세스 사이에서의 데이터 교환을 위해서는 별도의 IPC 기법을 적용해야 한다.
컨텍스트 스위칭(Context Switching)에 따른 부담은 프로세스 생성방식의 가장 큰 부담이다
CPU가 하나인(CPU의 연산장치인 CORE) 시스템에서 둘 이상의 프로세스가 동시에 실행되려면 CPU의 할당시간을 매우 작은 크기로 쪼개서 서로 나누어 사용해야 한다. 그런데 CPU의 할당시간을 나누기 위해서는 '컨텍스트 스위칭'이라는 과정을 거쳐야 한다.
프로그램의 실행을 위해서는 해당 프로세스의 정보가 메인 메모리에 올라와야 한다. 때문에 현재 실행중인 A프로세스의 뒤를 이어서 B프로세스를 실행시키려면 A프로세스 관련 데이터를 메인 메모리에서 그리고 B프로세스 관련 데이터를 메인 메모리로 이동시켜야 한다. 이것이 컨텍스트 스위칭이다. 그런데 이때 A프로세스 관련 데이터를 하드디스크로 이동하기 때문에 컨텍스트 스위칭에는 오랜 시간이 걸리고, 빨리 진행한다 하더라도 한계가 있다.
결국 멀티프로세스의 특징을 유지하면서 단점을 어느 정도 극복하기 위해서 '쓰레드(Thread)'라는 것이 등장하는데, 이는 멀티프로세스의 여러 가지 단점을 최소화하기 위해서 설계된 일종의 경량화된 프로세스이다. 쓰레드는 프로세스와 비교해서 다음과 같은 장점이 있다
쓰레드의 생성 및 컨텍스트 스위칭은 프로세스의 생성 및 컨텍스트 스위칭 보다 빠르다.
쓰레드 사이에서의 데이터 교환은 특별한 기법이 필요치 않다
쓰레드와 프로세스의 차이점
프로세스의 메모리 구조는 전역변수가 할당되는 '데이터 영역',
malloc 함수 등에 의해 동적 할당이 이뤄지는 '힙(haep) 영역',
함수의 실행에 사용되는 '스택(stack)영역'으로 이뤄진다.
프로세스들은 이를 완전히 별도로 유지된다. 때문에 프로세스 사이에서는 다음의 메모리 구조를 보인다.

그런데 둘 이상의 실행흐름을 갖는 것이 목적이라면, 위 그림처럼 완전히 메모리 구조를 분리시킬 것이 아니라, 스택 영역만 분리시킴으로써 다음의 장점을 얻을 수 있다.
1.컨텍스트 스위칭 시 데이터영역과 힙은 올리고 내릴 필요가 없다
2.데이터 영역과 힙을 이용해서 데이터를 교환할 수 있다.
그래서 등장한 것이 쓰레드이며, 모든 쓰레드는 별도의 실행흐름을 유지하기 위해서 스택 영역만 독립적으로 유지하기 때문에 다음의 메모리 구조를 보인다.
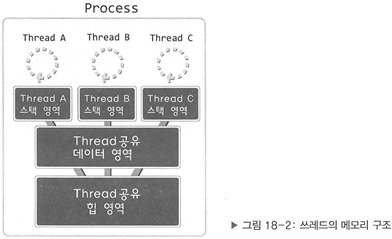
위 그림에서 보이듯이 데이터 영역과 힙 영역을 공유하는 구조로 쓰레드는 설계되어 있다. 그리고 이를 위해서 쓰레드는 프로세스 내에서 생성 및 실행되는 구조로 완성되었다. 즉, 프로세스와 쓰레드는 다음과 같이 정의할 수 있다.
프로세스 : 운영체제 관점에서 별도의 실행흐름을 구성하는 단위
쓰레드 : 프로세스 관점에서 별도의 실행흐름을 구성하는 단위
프로세스가 하나의 운영체제 안에서 둘 이상의 실행흐름을 형성하기 위한 도구라면, 쓰레드는 하나의 프로세스 내에서 둘 이상의 실행흐름을 형성하기 위한 도구로 이해할 수 있다.

쓰레드의 생성 및 실행
POSIX란 Potable Operating System Interface for Computer Environment의 약자로써 UNIX 계열 운영체제간에 이식성을 높이기 위한 표준 API 규격을 뜻한다. 그리고 쓰레드의 생성방법은 POSIX에 정의된 표준을 근거로 한다. 때문에 리눅스 뿐만 아니라, 유닉스 계열의 운영체제에서도 대부분 적용 가능하다.
쓰레드의 생성과 실행흐름의 구성
쓰레드는 별도의 실행흐름을 갖기 때문에 쓰레드만의 main함수를 별도로 정의해야 한다. 그리고 이 함수를 시작으로 별도의 실행흐름을 형성해 줄 것을 운영체제에게 요청해야 하는데, 이를 목적으로 호출하는 함수는 다음과 같다
#include <pthread.h>
int pthread_create(pthread_t *restrict thread, const pthread_attr_t* restrict attr, void*(*start_routine)(void*), void* restrict arg);
- 성공 : 0
- 실패 : 0 이외의 값 반환
thread
생성할 쓰레드의 ID 저장을 위한 변수의 주소 값 전달, 쓰레드는 프로세스와 마찬가지로 쓰레드의 구분을 위한 ID가 부여된다.
attr
쓰레드에 부여할 특성 정보의 전달을 위한 매개변수, NULL 전달 시 기본적인 특성의 쓰레드 생성
start_routine
쓰레드의 main함수 역할을 하는, 별도의 실행흐름으로 시작이 되는 함수의 주소값(함수 포인터) 전달
arg
세 번째 인자로 통해 등록된 함수가 호출될 때 전달할 인자의 정보를 담고 있는 변수의 주소 값 전달

쓰레드의 실행을 관리한다는 것은 프로그램의 흐름을 예측한다는 뜻인데, 이는 사실상 불가능한 일이다. 그리고 잘못된 구현은 프로그램의 흐름을 방해하는 결과로 이어질 수 있다. 이러한 문제점 때문에 sleep 함수보다는 다음 함수를 이용해서 쓰레드의 실행흐름을 조절한다. 즉, 다음 함수를 사용하면 지금 이야기하고 있는 문제를 쉽고 효율적으로 해결할 수 있다.
#include <pthrad.h>
int pthread_join(pthread_t thread, void** status);
- 성공 : 0
- 실패 : 0 이외의 값 반환
thread
이 매개변수에 전달되는 ID의 쓰레드가 종료될 때까지 함수는 반환하지 않는다
status
쓰레드의 main 함수가 반환하는 값이 저장될 포인터 변수의 주소값을 전달한다
위 함수는 첫 번째 인자로 전달되는 ID의 쓰레드가 종료될 때까지 이 함수를 호출한 프로세스(또는 스레드)를 대기상태에 둔다. 뿐만 아니라 threadMain함수가 반환하는 값까지 얻을 수 있으니 그만큼 유용함 함수이다.
예제 thread2.c
결과


임계영역 내에서 호출이 가능한 함수
함수 중에는 둘 이상의 쓰레드가 동시에 호출하면 문제를 일으키는 함수가 있다. 이는 함수 내에 '임계영역(Critical Section)'이라 불리는, 둘 이상의 쓰레드가 동시에 실행하면 문제를 일으키는 문장이 하나 이상 존재하는 함수이다. 이러한 임계영역의 문제와 관련해서 함수는 다음 두 가지 종류로 구분이 된다.
쓰레드에 안전한 함수(Thread-safe function)
쓰레드에 불안전한 함수(Thread-unsafe function)
여기서 쓰레드에 안전한 함수는 둘 이상의 쓰레드에 의해서 동시에 호출 및 실행되어도 문제를 일으키지 않는 함수를 뜻한다. 반대로 쓰레드에 불안전한 함수는 동시호출 시 문제가 발생할 수 있는 함수를 뜻한다.
대부분의 표준함수들은 쓰레드에 안전하다. 쓰레드에 불안전한 함수가 정의되어 있는 경우, 같은 기능을 갖는 쓰레드에 안전한 함수가 정의되어 있다.
일반적으로 쓰레드에 안전한 형태로 재 구현된 함수의 이름에는 _r이 붙는다.
헤더파일 선언 이전에 매크로 _REENTRANT를 정의하면 _r 함수의 호출로 자동화 할 수 있다.
워커(Worker) 쓰레드 모델
예제 thread3.c
쓰레드의 문제점과 임계영역(Critical Section)
하나의 변수에 둘 이상의 쓰레드가 동시에 접근하는 것이 문제
예제 thread4.c
예제 thread4.c는 "전역 변수 num에 둘 이상의 쓰레드가 함께(동시에) 접근하고 있다"라는 문제점이 있다.
여기서 말하는 접근이란 주로 값의 변경을 뜻한다. 그런데 다양한 상황에서 문제가 발생할 수 있기 때문에 문제의 원인이 무엇인지 정확히 이해해야 한다. 그리고 예제에서는 접근의 대상이 전역변수였지만, 이는 전역변수였기 때문에 발생한 문제가 아니다. 어떠한 메모리 공간이라도 동시에 접근을 하면 문제가 발생할 수 있다.

쓰레드 동기화
동기화의 두 가지 측면
쓰레드의 동기화는 쓰레드의 접근순서 때문에 발생하는 문제점의 해결책을 뜻한다. 그런데 동기화가 필요한 상황은 다음 두 가지 측면에서 생각해 볼 수 있다.
1.동일한 메모리 영역으로의 동시접근이 발생하는 상황
2.동일한 메모리 영역에 접근하는 쓰레드의 실행순서를 지정해야 하는 상황
두 번째 상황은 쓰레드의 '실행 순서 컨트롤(Contrl)'에 관련된 내용이다. 실행 순서의 컨트롤이 필요한 상황에서도 동기화 기법이 활용된다.
뮤텍스(Mutex)
뮤텍스란 'Mutual Exclusion'의 줄임 말로써 쓰레드의 동시접근을 허용하지 않는다는 의미가 있다. 뮤텍스는 쓰레드의 동기접근에 대한 해결책으로 주로 사용된다.
뮤텍스라 불리는 자물쇠 시스템의 생성 및 소멸 함수는 다음과 같다.
#include <pthread.h>
int pthread_mutex_init(pthread_mutex_t* mutex, const pthread_mutexattr_t* attr);
int pthread_mutex_destroy(pthread_mutex_t* mutex);
- 성공 : 0
- 실패 : 0이외의 값 반환
mutex
뮤텍스 생성시에는 뮤텍스의 참조 값 저장을 위한 변수의 주소값 전달, 소멸시에는 소멸하고자 하는 뮤텍스의 참조값을 저장하고 있는 변수의 주소 값 전달
attr
생성하는 뮤텍스의 특성정보를 담고 있는 변수의 주소 값 전달, 별도의 특성을 지정하지 않을 경우 NULL 전달
예제 mutex.c
세마포어(Semaphore)
#include <semaphore.h>
// 성공 시 0, 실패 시 0 이외의 값 반환
int sem_init(sem_t *sem,
int pshared,
unsigned int value);
int sem_destroy(sem_t *sem);
sem : 세마포어 생성시에는 세마포어의 참조 값 저장을 위한 변수의 주소 값 전달, 그리고 세마포어 소멸 시에는 소멸하고자 하는 세마포어의 참조 값을 저장하고 있는 변수의 주소 값 전달.
pshared : 0 이오의 값 전달 시, 둘 이상의 프로세스에 의해 접근 가능한 세마포어 생성, 0 전달 시 하나의 프로세스 내에서만 접근 가능한 세마포어 생성, 여기서는 하나의 프로세스 내에 존재하는 쓰레드의 동기화가 목적이므로 0을 전달한다.
value : 생성되는 세마포어의 초기 값 지정.
#.뮤텍스 lock, unlock 에 해당하는 세마포어 관련 함수
#include <semaphore.h>
// 성공 시 0, 실패 시 0 이외의 값 반환
int sem_post(sem_t *sem);
int sem_wait(sem_t *sem);
sem : 세마포어의 참조 값을 저장하고 있는 변수의 주소 값 전달, sem_post에 전달되면 세마포어의 값은 하나 증가, sem_wait에 전달되면 세마포어의 값은 하나 감소.
#.세마포어 메커니즘
sem_init 함수가 호출되면 운영체제에 의해서 세마포어 오브젝트라는 것이 만들어 지는데, 이곳에는 세마포어 값(Semaphore value)이라 불리는 정수가 하나 기록됨.
그리고 이 값은
sem_post 함수가 호출되면 1 증가
sem_wait 함수가 호출되면 1 감소
단 세마포어 값은 0보다 작아질 수 없기 때문에 현재 0인 상태에서 sem_wait 함수를 호출하면, 호출한 쓰레드는 함수가 반환되지 않아서 블로킹 상태에 놓이게 된다. 물론 다른 쓰레드가 sem_post 함수를 호출하면 세마포어의 값이 1이 되므로, 이 1을 0으로 감소시키면서 블로킹 상태에서 빠져나가게 함.
sem_wait(&sem); // 세마포어 값을 0으로..
// 임계영역의 시작
// ....
// 임계영역의 끝
sem_post(&sem); // 세마포어 값을 1로...
#.세마포어 사용 예제
쓰레드 A가 프로그램 사용자로부터 값을 입력 받아서 전역변수 num에 저장을 하면, 쓰레드 B는 이 값을 가져다가 누적해 나간다. 이 과정은 총 5회 진행이 되고, 진행이 완료되면 총 누적금액을 출력하면서 프로그램은 종료된다.
쓰레드의 소멸과 멀티쓰레드 기반의 다중접속 서버의 구현
쓰레드를 소멸하는 세 가지 방법
1.리눅스의 쓰레드는 처음 호출하는, 쓰레드의 main 함수를 반환했다고 해서 자동으로 소멸되지 않는다.
때문에 다음 두 가지 방법 중 하나를 택해서 쓰레드의 소멸을 직접적으로 명시해야 한다.
그렇지 않으면 쓰레드에 의해서 할당된 메모리 공간이 계속해서 남아있게 된다.
2.pthread_join 함수의 호출
쓰레드의 종료를 대기할 뿐만 아니라, 쓰레드의 소멸까지 유도된다. 이 함수의 문제점은 쓰레드가 종료될 때까지 블로킹 상태에 놓이게 된다.
3.pthread_detach 함수의 호출
일반적으로는 다음 함수의 호출을 통해서 쓰레드의 소멸을 유도한다.
#.pthread_detach 함수
이 함수를 호출했다고 해서 종료되지 않은 쓰레드가 종료되거나, 블로킹 상태에 놓이지 않는다.
이 함수가 호출된 이후에는 해당 쓰레드를 대상으로 pthread_join 함수의 호출이 불가능하다.
#include <pthread.h>
// 성공 시 0, 실패 시 0 이외의 값 반환
pthread_detach(pthread_t thread);
thread : 종료와 동시에 소멸시킬 쓰레드의 ID정보 전달.
예제 server.c
예제 client.c
[출처] : 윤성우 저, "열혈강의 TCP/IP 소켓 프로그래밍", 오렌지미디어
'컴퓨터 기초 > TCP&IP' 카테고리의 다른 글
| 19.C언어 HTTP 서버 구축하기 (표준입출력 이용) (0) | 2020.08.27 |
|---|---|
| 18.http 서버 (0) | 2020.08.24 |
| 16.입출력 스트림의 분리에 대한 나머지 이야기 (0) | 2020.08.19 |
| 15.소켓과 표준 입출력 (0) | 2020.08.19 |
| 14.멀티캐스트 & 브로드캐스트 (0) | 2020.08.18 |



