해시테이블은 이진 탐색보다 훨씬 빠른 성능을 자랑하지만, 그만큼 더 많은 메모리를 요구한다.
해시는 해시 테이블뿐 아니라 문자열 탐색, 암호화 등 다른 알고리즘에 많이 응용되는 알고리즘이다.
학습목표
- 해시의 개념을 이해한다.
- 해시 테이블의 개념과 구현을 이해한다.
- 해시 함수의 개념과 구현을 이해한다.
- 해시 테이블의 주소 충돌 해결 방법을 이해한다.
해시의 영어뜻은 "잘게 자른 고기를 양파나 감자와 같은 다른 재료와 함께 튀겨 한 덩어리로 만든요리" 이다.
즉, 해시는 데이터를 입력 받아 완전히 다른 모습의 데이터로 바꾸는 작업이다.
1.해시 테이블 : 해시 테이블은 데이터의 해시값을 테이블 내 주소로 이용하는 궁극의 탐색 알고리즘이다.
2.암호화 : 해싱은 원본 데이터를 다른 모습으로 바꿔놓는다.
해싱은 같은 데이터에 대해 같은 결과를 출력하지만, 다른 데이터에 대해서는 다른 결과를 출력한다.
말하자면 해시는 데이터의 지문 역할을 할 수 있다.
이런 특징 때문에 해시는 디지털 서명이나 블록체인에 많이 사용되고 있다.
MD5, SHA 알고리즘이 대표적인 예이다.
3.데이터 축약 : 해시는 길이가 서로 다른 입력 데이터에 대해 일정한 길이의 출력을 만들 수 있다.
이 특성을 이용하여 커다란 데이터를 '해시'하면 짧은 길이로 축약할 수 있다.
이렇게 축약된 데이터끼리 비교를 수행하면 커다란 원본 데이터끼리 비교하는 것에 비해 효율이 매우 놓아진다.
배열에서 인덱스 40번의 값을 찾기는 쉽고 빠르다.
하지만 123817 값을 찾는다고 하면?
순차 탐색을 하거나 배열을 정렬한 뒤 이진 탐색을 해야 한다.

이런 방법이 금융과 같은 분야에서는 성능이 용납되지 않을 수 있다.
해시 테이블은 아주 간단한 개념을 도입해서 이 문제를 해결한다.
바로 데이터의 '해시'값을 테이블 내의 주소로 사용하는 것이다.
데이터가 해시 함수를 거치면 아래 그림처럼 테이블 내의 주소(인덱스)로 변환한다.

이 그림에서 123817을 해싱하여(잘게 쪼개고 다시 뭉쳐서) 얻은 주소 값이 3819이다.
이제 아래와 같이 Table 내의 해당 주소(인덱스)에 데이터를 저장하면 된다.

데이터를 읽는 것도 마찬가지다.


데이터를 담을 테이블을 미리 크게 확보해놓은 후 입력 받은 데이터를 해싱하여 테이블 내 주소를 계산하고 이 주소에 데이터를 담는것.
이것이 바로 해시 테이블의 기본 개념이다.
해시 테이블은 배열과 다름 없는 접근 속도를 자랑한다.
해시 테이블의 성능은 공간과 맞바꾼것이다.
참고로 해시 테이블은 데이터가 입력되지 않은 여유 공간이 많아야 제 성능을 유지할 수 있다.

해시가 어떻게 데이터로부터 테이블 내의 주소값을 뽑아낼까?
해시함수
입력값에서 테이블 내의 주소를 계산하는 해시 함수
나눗셈법 (해시함수)
나눗셈법은 해시 함수 중에서도 가장 간단한 알고리즘이다.

나눗셈법의 구현
어떤 값이든 테이블의 크기로 나누면 그 나머지는 테이블의 크기를 절대 넘지 않는다.
입력값이 테이블 크기의 배수 또는 약수인 경우 해시 함수는 0을 반환하고 그렇지 않은 경우에는 최대 n - 1을 반환한다.
즉, 나눗셈법은 0부터 n - 1 사이의 주소 반환을 보장한다.

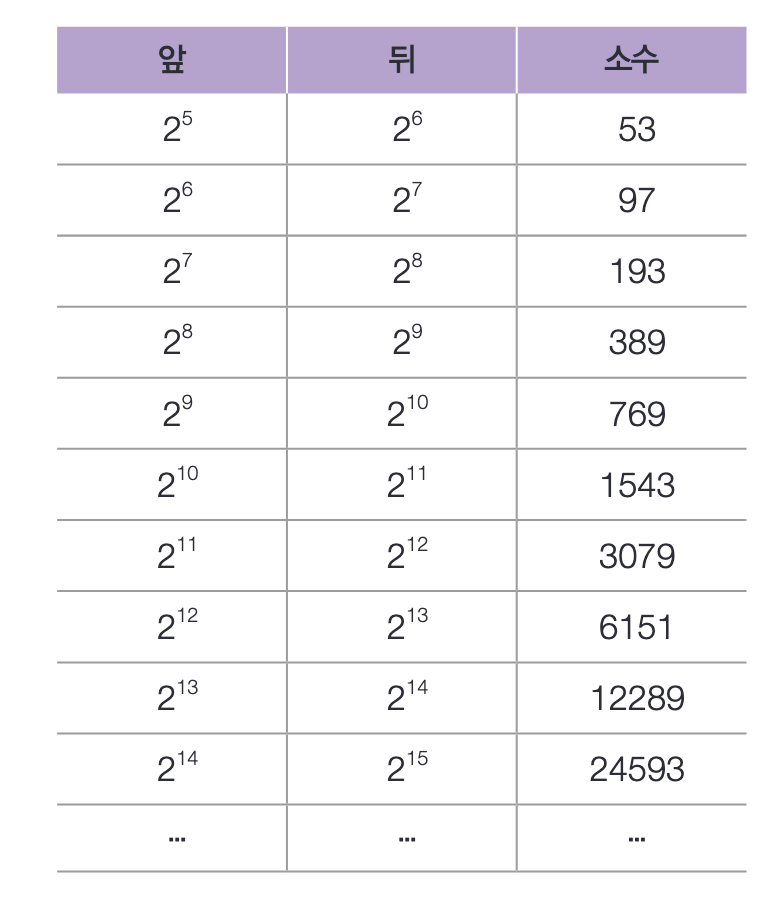
크기가 193일 때 데이터가 9인 경우 9를 반환하고, 418일 때 32, 1031일 때 66 을 반환한다.
하지만 왜 배열의 크기를 193으로 했을까?

나눗셈법으로 구현된 해시 함수가 테이블 내 공간을 효율적으로 사용하기 위해서는 테이블의 크기 n을 소수로 정하는 것이 좋다고 알려져 있다.
특히 2의 제곱수와 거리가 먼 소수를 사용하는 해시 함수가 좋은 성능을 낸다.
key는 주소로 사용할 데이터, value는 key로 얻어낸 주소에 저장할 데이터.
key를 주소로 사용하는 것이 아니라 해시 함수에 Key를 넣어 계산된 결과를 주소로 사용하는 것이다.



자리수 접기
나눗셈법도 단점이 있다.
바로 서로 다른 입력값에 대해 동일한 해시값, 즉 해시 테이블 내의 동일한 주소를 반환할 가능성이 높다.
이것을 충돌이라고 한다.
똑같은 해시값이 아니더라도 해시 테이블 내 일부 지역의 주소들을 집중적으로 반환함으로써 데이터가 한 곳에 모이는 문제인 클러스터가 발생할 가능성이 높다.
그래서 자릿수 접기 방법을 사용한다.

위의 수를 한자리씩 더해보기

이번에는 두 자리씩 더해보기
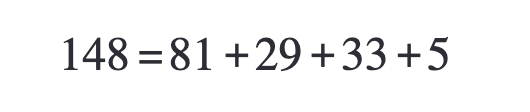
이처럼 숫자의 각 자릿수를 더해 해시값을 만드는 것을 자릿수 접기라고 한다.
자릿수 접기 역시 나눗셈법처럼 일정한 범위 내의 해시값을 얻을 수 있다.
10진수의 경우 모든 수는 각 자리마다 0 ~ 9까지의 값을 가질 수 있으므로, 7자리수에 대해 '한 자리씩 접기'를 하면 최소 0 에서 최대 63 (9 + 9 + 9 + 9 + 9 + 9) 까지의 해시값을 얻을 수 있고,
'두 자리씩 접기'를 하면 최소 0에서 최대 306(99 + 99 + 99 + 9) 까지의 해시값을 얻을 수 있다.
자릿수 접기는 문자열을 키로 사용하는 해시 테이블에 특히 잘 어울리는 알고리즘이다.
문자열의 각 요소를 ASCII 코드 번호로 바꾸고, 이 값들을 각각 더해서 접으면 문자열을 깔끔하게 해시 테이블의 주소로 바꿀 수 있기 때문이다.


이 코드에 한 가지 문제가 있다.
예를 들어 해시 테이블의 크기가 12289 이고 문자열 키의 최대 길이가 10자리라고 한다면 해시 함수는 10 * 127 = 1270 이므로
0 에서 1270 사이의 주소만 반환하게 된다.
즉, 1271 ~ 12288 사이의 주소는 전혀 활용되지 않는다.
테이블의 크기 12289를 2진수로 표현하면 14비트다.
위의 Hash() 함수가 반환하는 최대 주소값은 1270은 이진수로 11비트만 사용한다.
즉, 테이블의 주소 중 3개의 비트는 사용되지 않는다는 사실을 알 수 있다.
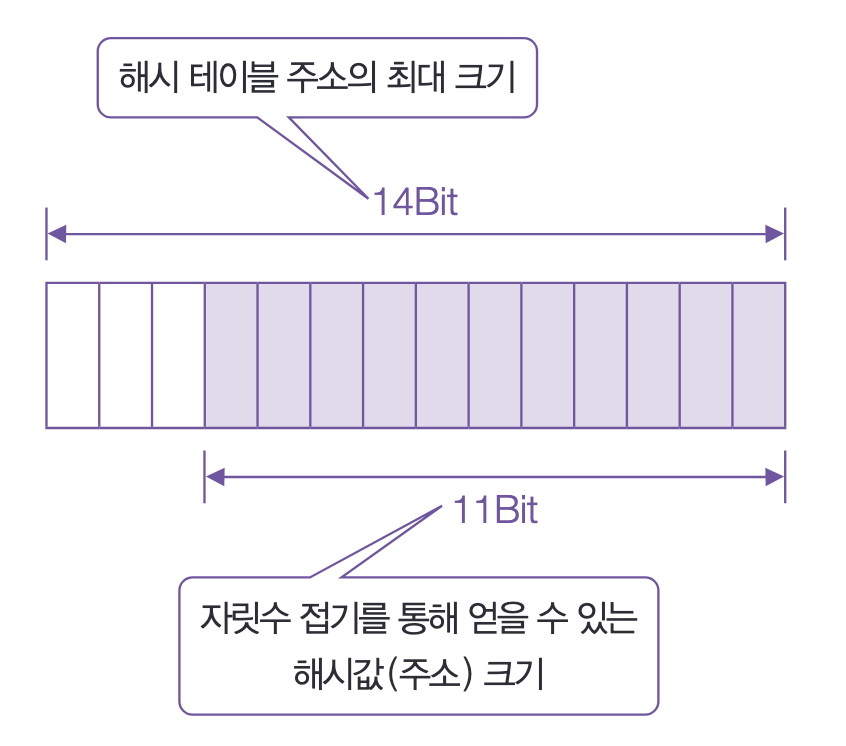
문제의 핵심은 놀고 있는 3개의 비트를 모두 활용한다면 위에서 이야기했던 해시테이블의 문제를 해결할 수 있다.
아래 함수는 Hash() 루프가 반복될 때마다 HashValue를 왼쪽으로 3비트씩 밀어올린 다음 ASCII 코드 번호를 더한다.
이렇게 하면 Hash() 함수는 이론적으로 해시 테이블 내의 모든 주소를 해싱할 수 있다.

해시 함수의 한계 : 충돌
해시 함수는 서로 다른 입력값에 대해 동일한 해시 테이블 주소를 반환한다. 이것을 '충돌' 이라고 한다.
예) 테이블의 크기가 12289일때 WJLY 를 입력해도 10871, SZSR을 입력해도 10871이 반환 된다.
충돌 해결 기법
1. 해시 테이블의 주소 바깥에 새로운 공간을 할당하여 문제를 수습하는것. (개방 해싱)
2.처음에 주어진 해시 테이블의 공간 안에서 문제를 해결하는것.(폐쇄 해싱)
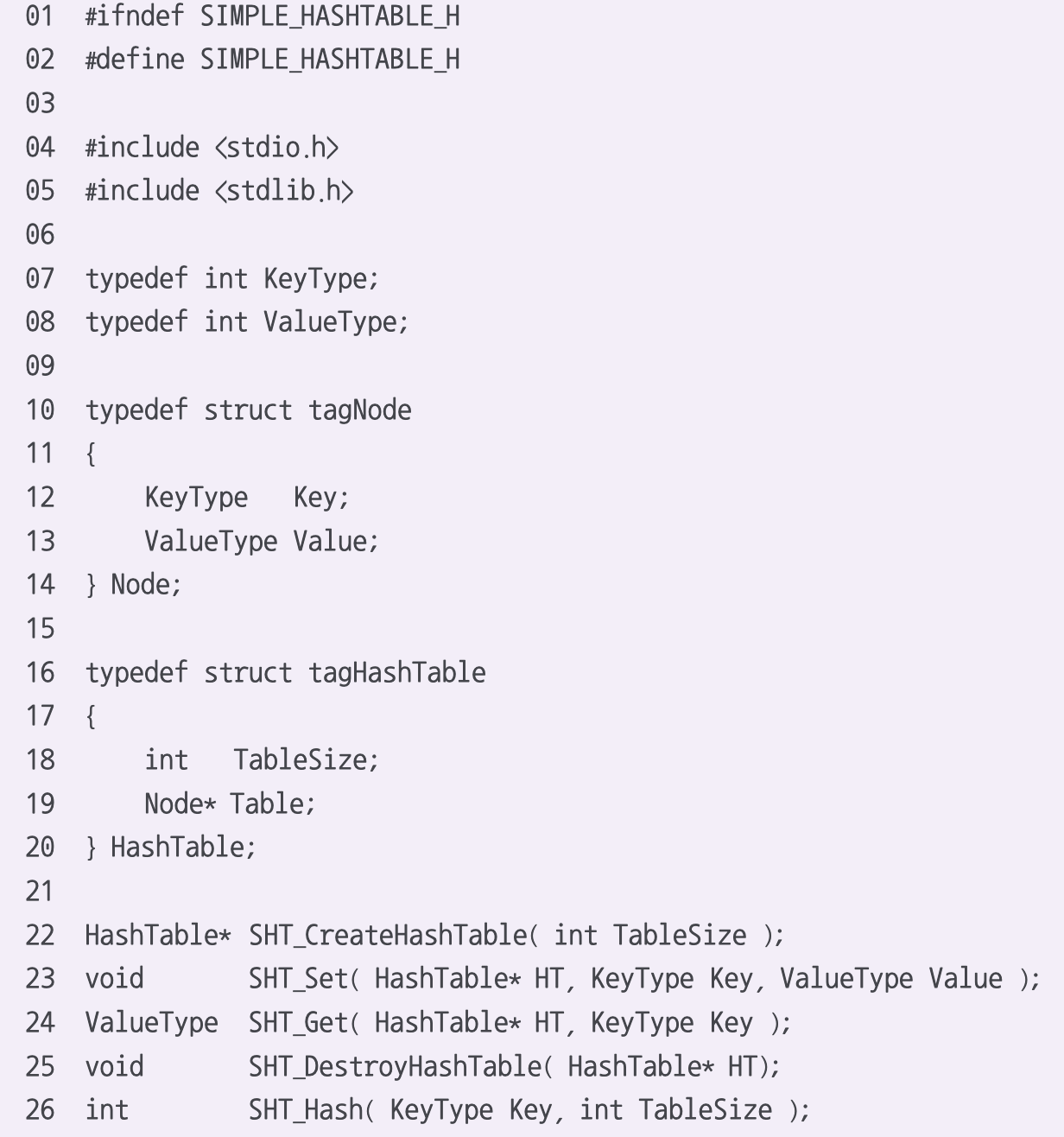
예제 코드
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
typedef int KeyType;
typedef int ValueType;
typedef struct tagNode{
KeyType Key;
ValueType Value;
}Node;
typedef struct tagHashTable{
int TableSize;
Node* Table;
} HashTable;
HashTable* createHashTable(int size);
void set(HashTable* HT, KeyType Key, ValueType Value);
ValueType get(HashTable* HT, KeyType Key);
void destroyHashTable(HashTable* HT);
int hash(KeyType Key, int TableSize);
int hash(char* Key, int keySize , int TableSize);
//MARK: 생성
HashTable* createHashTable(int size){
HashTable* ht = (HashTable*)malloc(sizeof(HashTable));
if (ht == NULL) {
printf("HashTable 메모리 생성에 실패했습니다.\n");
return NULL;
}
ht->Table = (Node*)malloc(sizeof(Node) * size);
if(ht->Table == NULL){
printf("Table 메모리 생성에 실패했습니다.\n");
free(ht);
return NULL;
}
ht->TableSize = size;
return ht;
}
//MARK: 해싱: 나눗셈법
int hash(KeyType Key, int TableSize){
return Key % TableSize;
}
//MARK: 해싱: 자리수접기1
int hash(char* Key, int keySize , int TableSize){
//문자열을 깔끔하게 해시 테이블의 주소로 바꾸기
//문자열에 사용되는 ASCII 코드 번호는 0 ~ 127 사이의 값을 가진다.
int i = 0;
int hashValue = 0;
//문자열의 각 요소를 ASCII 코드로 변환하여 더한다.
for (i = 0; i < keySize; i++) {
hashValue += Key[i];
}
return hashValue % TableSize;
}
//MARK: 해싱: 자리수접기2
int hash2(char* Key, int keySize , int TableSize){
/*
만약 해시 테이블의 크기가 12289 이고, 문자열 키의 최대 길이가 10자리라고 한다면
해시 함수는 10 * 127 = 1270 이므로 0 에서 1270 사이의 주소만 반환하게 된다.
이러면 1271 ~ 12288 사이의 주소는 전혀 활용되지 않는다.
이 문제를 해결 하기 위해서, 즉 모든 비트를 활용할 수 있도록 왼쪽으로 3비트씩 밀어올린다음 ASCII 코드를 더한다.
*/
int i = 0;
int hashValue = 0;
//문자열의 각 요소를 ASCII 코드로 변환하여 더한다.
for (i = 0; i < keySize; i++) {
hashValue = (hashValue << 3) + Key[i];
}
return hashValue % TableSize;
}
//MARK: 삽입
void set(HashTable* HT, KeyType Key, ValueType Value){
int address = hash(Key, HT->TableSize);
HT->Table[address].Key = Key;
HT->Table[address].Value = Value;
}
//MARK: 추가
ValueType get(HashTable* HT, KeyType Key){
int address = hash(Key, HT->TableSize);
return HT->Table[address].Value;
}
//MARK: 소멸
void destroyHashTable(HashTable* HT){
free(HT->Table);
free(HT);
}
//MARK: main
int main(int argc, const char * argv[]) {
HashTable* HT = createHashTable(193);
set(HT, 418, 32114);
set(HT, 9, 514);
set(HT, 27, 8917);
set(HT, 1031, 286);
printf("key: %d , value: %d\n" , 418 , get(HT, 418));
printf("key: %d , value: %d\n" , 9 , get(HT, 9));
printf("key: %d , value: %d\n" , 27 , get(HT, 27));
printf("key: %d , value: %d\n" , 1031 , get(HT, 1031));
return 0;
}
출력
key: 418 , value: 32114
key: 9 , value: 514
key: 27 , value: 8917
key: 1031 , value: 286
Program ended with exit code: 0
'컴퓨터 기초 > C언어' 카테고리의 다른 글
| [C언어]58일차 - 이중해싱 (0) | 2025.12.05 |
|---|---|
| [C언어]57일차 - 해시 체이닝 (0) | 2025.12.04 |
| [C언어]54 - 55일차- 힙 자료구조 (이것이 c 자료구조와 알고리즘이다) (0) | 2025.11.27 |
| [C언어]53일차-이진트리 노드삽입 삭제 (이것이 c 자료구조와 알고리즘이다) (0) | 2025.11.26 |
| [C언어]52일차-이진탐색과 이진탐색트리 (이것이 c 자료구조와 알고리즘이다) (0) | 2025.11.25 |



