분리집합은 서로 공통된 원소를 갖지 않는, 즉 교집합을 갖지 않는 복수의 집합을 뜻한다.
그래서 분리 집합의 개념은 2개 이상의 집합을 일컬을 때만 사용할 수 있다.
아래는 분리 집합의 예이다.
분리 집합에는 교집합이 있을 수 없다.

분리 집합에는 합집합만 있을 뿐이다.
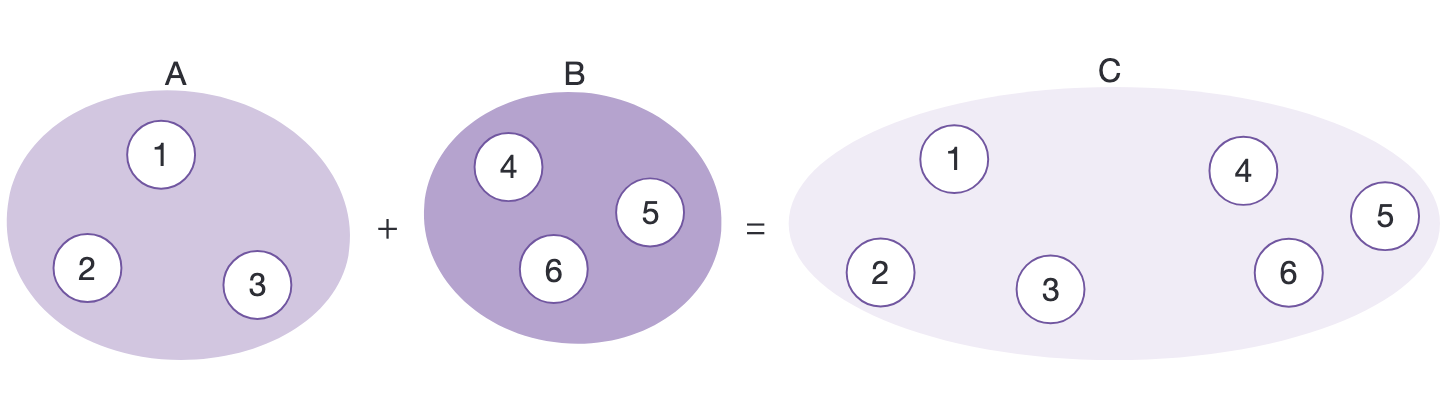
위의 내용을 어디에 사용할 수 있나?
아래와 같은 도서 판매 관리 프로그램을 만들었다. 그리고 책의 정보는 아래와 같은 자료구조로 정의 했다.

상황) 사장이 가게 홍보를 위해 일주일간 베스트 셀러만 책 가격을 할인하기로 함.
행사는 임시적이기 때문에 BookPrice 구조체의 Price 값을 바꿔서는 안된다.
구조체에 베스트셀러임을 나타내는 필드를 추가하는 일은 프로그램의 다른 부분에 부작용을 미칠 수 있어서 안된다.
이때,
분리집합을 이용해서 '일반도서 집합' 과 '베스트 셀러 집합'을 만들고 베스트셀러들의 BookPrice가 베스트셀러 집합의 원소가 되게 하는 방법으로 처리 할 수 있다.
즉, 해당 BookPrice 개체가 베스트셀러 집합에 속해 있는지 여부만 알면 할인 가격으로 판매할지 원래 가격으로 판매할지 알 수 있다.
분리 집합은 원소 또는 개체가 '어느 집합에 소속되어 있는가?' 라는 정보를 바탕으로 무언가를 하는 알고리즘에 응용할 수 있다.
분리집합 표현
지금까지 이진 트리는 부모가 자식을 가리키는 포인터를 갖고 있었다.
분리 집합은 이와 반대로 자식이 부모를 가리킨다.

뿌리 노드는 집합 그 자체이고, 뿌리 노드 자신을 포함한 트리 내의 모든 노드는 그 집합에 소속 된다.
링크드 리스트에서 헤드 노드가 링크드 리스트를 나타낸다는 점을 떠올려 보면 이해에 도움이 될 수 있다.
위의 설명처럼 자식 노드에 대한 포인터는 없고, 오로지 부모 노드에 대한 포인터만 있다.
뿌리 노드는 부모가 없으므로 Parent가 NULL 이다.

분리 집합의 기본 연산
분리 집합의 연산은 딱 두가지다.
합집합 연산과 집합 탐색 연산.
"분리 집합의 목적은 원소가 어느 집합에 귀속되어 있는지 쉽게 알아내는 데 있기 때문이다."
합집합 연산
트리로 구현되어 있는 분리 집합을 어떻게 합칠 수 있을까?
집합을 이루는 트리 내의 모든 노드는 뿌리 노드가 나타내는 집합 안에 있다.
따라서 아래처럼 두 집합을 합친다고 하면, 오른쪽에 있는 집합의 뿌리 노드를 왼쪽에 있는 뿌리 노드의 자식 노드로 만들면 된다.

집합 탐색 연산
분리 집합의 탐색은 집합에서 원소를 찾는 것이 아니라 원소가 속한 집합을 찾는 연산이다.
집합내 어떤 노드에게든 트리의 최상위에 있는 뿌리 노드가 곧 자신이 속한 집합을 나타내므로
해당 원소(노드)가 어떤 집합에 속해 있는지 알려면 이 원소가 속한 트리의 뿌리 노드를 찾으면 된다.
분리집합의 각 노드는 부모 노드를 가리키는 포인터를 갖고 있다.
이 포인터를 타고 쭉 올라가면 부모가 NULL인 뿌리 노드를 만날 수 있다.
이 뿌리 노드는 곧 집합을 나타내므로 이것을 반환하면 해당 노드가 소속된 집합을 반환하게 되는 것이다.

전체코드
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
typedef struct _DisjointSet{
struct _DisjointSet* Parent;
void* Data;
}DisjointSet;
void unionSet(DisjointSet* set1, DisjointSet* set2);
DisjointSet* findSet(DisjointSet* set);
DisjointSet* makeSet(void* newData);
void destroySet(DisjointSet* set);
//MARK: 생성
DisjointSet* makeSet(void* newData){
DisjointSet* newSet = (DisjointSet*)malloc(sizeof(DisjointSet));
newSet->Data = newData;
newSet->Parent = NULL;
return newSet;
}
//MARK: 합집합 연산
void unionSet(DisjointSet* set1, DisjointSet* set2){
DisjointSet* parentMainSet = findSet(set1);
DisjointSet* parentSubSet = findSet(set2);
parentSubSet->Parent = parentMainSet;
}
//MARK: 부모찾기
DisjointSet* findSet(DisjointSet* set){
DisjointSet* parent = set;
while (parent->Parent != NULL) {
parent = parent->Parent;
}
return parent;
}
//MARK: 소멸
void destroySet(DisjointSet* set){
free(set);
}
//MARK: main
int main(int argc, const char * argv[]) {
int a = 1, b = 2, c = 3, d = 4;
DisjointSet* set1 = makeSet(&a);
DisjointSet* set2 = makeSet(&b);
DisjointSet* set3 = makeSet(&c);
DisjointSet* set4 = makeSet(&d);
printf("set1 == set2 : %d \n" , findSet(set1) == findSet(set2));
unionSet(set1, set3);
printf("set1 == set3 : %d \n" , findSet(set1) == findSet(set3));
unionSet(set3, set4);
printf("set3 == set4 : %d \n" , findSet(set3) == findSet(set4));
return 0;
}
출력결과
set1 == set2 : 0
set1 == set3 : 1
set3 == set4 : 1
Program ended with exit code: 0
'컴퓨터 기초 > C언어' 카테고리의 다른 글
| [C언어]51일차 - 순차탐색 (이것이 c 자료구조와 알고리즘이다) (0) | 2025.11.24 |
|---|---|
| 동적 메모리 할당 및 해제 (0) | 2025.11.21 |
| 메모리 할당 (0) | 2025.11.20 |
| [C언어]49일차 - 수식트리 (이것이 c 자료구조와 알고리즘이다) (0) | 2025.11.20 |
| [C언어]48일차 - 배열과 포인터 (0) | 2025.11.19 |



