이전 포스팅에서는 왼쪽자식 - 오른쪽 형제 표현법을 이용하여 하나의 노드가 N개의 자식 노드를 가질 수 있는 트리를 구현 했다.
이번 포스팅에서는 트리에서 하나의 노드가 자식 노드를 2개까지만 가질 수 있는 이진 트리를 알아본다.
이진트리 자료구조를 이용한 수식 이진 트리와 아주 빠른 데이터 검색을 가능하게 하는 이진 탐색 트리 알고리즘이 있다.
이진 트리의 종류
이진 트리의 가장 중요한 특징은 노드의 최대 차수가 2라는 사실이다.
즉, 모든 이진 트리 노드의 자식 노드 수는 0, 1, 2 중 하나다.
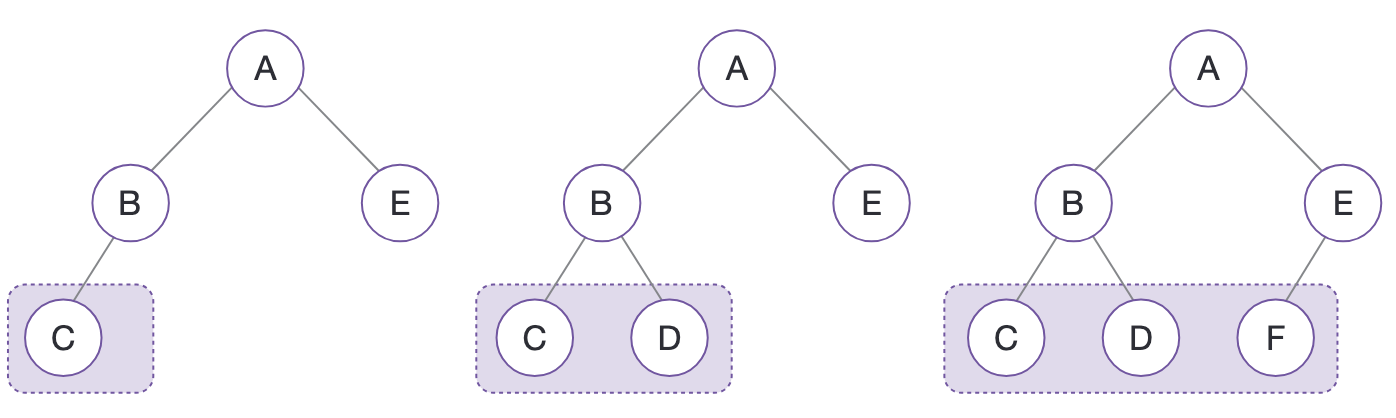
잎노드를 제외한 모든 노드가 자식을 둘씩 가진 이진 트리를 포화 이진 트리라고 한다.
포화 이진 트리는 잎 노드들이 모두 같은 깊이에 위치한다는 특징을 가진다.

포화 이진 트리와 비슷하지만 포화 이진 트리로 진화하기 전 단계의 트리도 있다.
이 트리를 완전 이진 트리라고 하는데, 잎 노드들이 트리 왼쪽부터 차곡차곡 채워진 것이 특징이다.
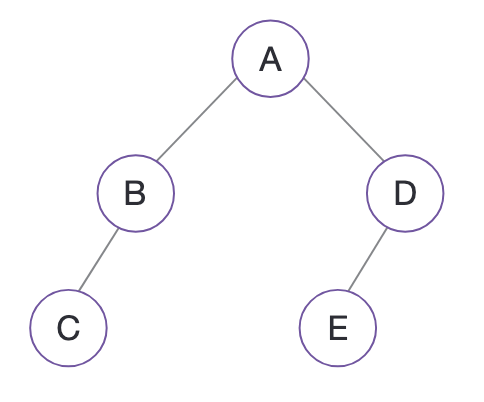
아래 트리는 완전 이진트리가 아니다.
이진 트리는 일반 트리처럼 나무 모양의 자료(예, 조직도)를 담기 위한 자료구조가 아니라 컴파일러나 검색과 같은 알고리즘의 뼈대가 되는 특별한 자료구조이다.
특히 이진 트리를 이용한 검색에서는 트리의 노드를 가능한 한 완전한 모습으로 유지해야 높은 성능을 낼 수 있다.
그래서 우리는 완전한 모습의 트리가 무엇인지 알고 있어야 한다.
높이 균형 트리
아래 그림과 같이 뿌리 노드를 기준으로 왼쪽 하위 트리와 오른쪽 하위 트리의 높이가 2 이상 차이 나지 않는 이진 트리를 말한다.

완전 높이 균형 트리
뿌리 노드를 기준으로 왼쪽 하위 트리와 오른쪽 하위 트리의 높이가 같은 이진 트리를 가리킨다.

이진 트리의 순회
순회는 간단히 말해 트리 안에서 노드 사이를 이동하는 연산이라고 할 수 있다.
전위 순회
1.뿌리 노드부터 시작하여 아래로 내려오면서
2.왼쪽 하위 트리를 방문하고
3.오른쪽 하위 트리를 방문하는 방식이다.

위 순회를 수행하면 뿌리 노드인 A노드 부터 방문하고 왼족 하위 트리인 B - C - D 노드를 방문한 후, E - F - G를 방문한다.

왼쪽 하위 트리 (B, C, D)의 뿌리 노드는 B이다.
그리고 B, C, D 트리의 왼쪽 하위 트리는 C이고
오른쪽 하위 트리는 D이다.
전위 순회는 이 하위 트리에서도 뿌리 노드 - 왼쪽 하위 트리 - 오른쪽 하위 트리 순으로 방문한다.
그래서 B를 먼저 방문한 후 왼쪽 하위 트리인 C를 방문하고 마지막으로 D를 방문하는 것이다.
이 규칙은 오른쪽 하위 트리에도 마찬가지로 적용된다.
전위 순회를 이용하면 이진 트리를 중첩된 괄호로 표현할 수 있다.
뿌리부터 시작해서 방문하는 노드의 깊이가 깊어질 때마다 괄호를 한 겹씩 두르면, 그림에 있는 트리가 다음과 같은 형식으로 표현된다.

중위 순회
1.왼쪽 하위 트리부터 시작해서
2.뿌리를 거쳐
3.오른쪽 하위 트리를 방문하는 방법
왜 노드가 아닌 하위 트리부터 방문을 하는 것일까?
트리가 하위 트리의 집합이라고 가정하면 하위 트리 역시 또 다른 하위 트리의 집합이라고 할 수 있다.
하위 트리가 또 다른 하위 트리로 분기할 수 없을 때까지, 즉 하위 트리가 잎 노드밖에 없을 때까지 하위 트리들이 계속 이어지는 것이다.
따라서 왼쪽 하위 트리부터 시작한다는 말은 트리에서 가장 왼쪽의 '잎 노드' 부터 시작한다는 뜻이다.
이 잎 노드에서 부터 시작된 순회는 부모 노드를 방문한 후 자신의 형제 노드를 방문하는 것으로 이어진다.
이렇게 해서 최소 단위의 하위 트리 순회가 끝나면 그 위 단계 하위 트리에 대해 순회를 이어간다.

중위 순회가 응용되는 대표 사례는 수식 트리이다.
(1 * 2) + (7 - 8) 을 수식 트리로 표현하면 다음 그림과 같이 나타낼 수 있다.

후위 순회
후위 순회의 방문 순서는 왼쪽 하위 트리 - 오른쪽 하위 트리 - 뿌리 노드 순이다.
그리고 이 순서는 하위 트리의 하위 트리, 또 그 하위 트리의 하위 트리에 대해서 똑같이 적용된다.
하위 트리가 잎 노드라면 방문은 중지 된다.

후위 순회로 아래 각 노드들을 방문하면서 노드에 담긴 값을 출력하면 어떤 결과가 나올까?

2장에서 다뤘던 후위 표기식처럼 출력이 된다.
같은 트리에 대해서 중위 순회로 노드에 담긴 값을 출력하면 중위 표기식이 나오고, 후위 순회를 거치면 후위 표기식이 출력된다.

이진 트리의 기본 연산
노드 선언

노드 생성
malloc() 함수로 자유 저장소에 SBTNode 구조체의 크기만큼 메모리 공간을 할당하고, 이렇게 할당한 메모리 공간을 NewNode 포인터에 저장한다.
각 필드들을 초기화 해주고, NewNode를 반환해준다.

소멸 연산

전위 순회를 응용한 이진 트리 출력
전위 순회는 뿌리 노드 부터 잎 노드까지, 즉 위에서 아래로 타고 내려오는 순회 규칙이다.


중위 순회를 응용한 이진 트리 출력
중위 순회는 왼쪽 하위 트리 - 뿌리 노드 - 오른쪽 하위 트리 순으로 방문한다.

후위 순회를 응용한 이진 트리 출력
후위 순회는 왼쪽 하위 트리 - 오른쪽 하위 트리 - 뿌리 순으로 방문하는 순회 규칙이다.

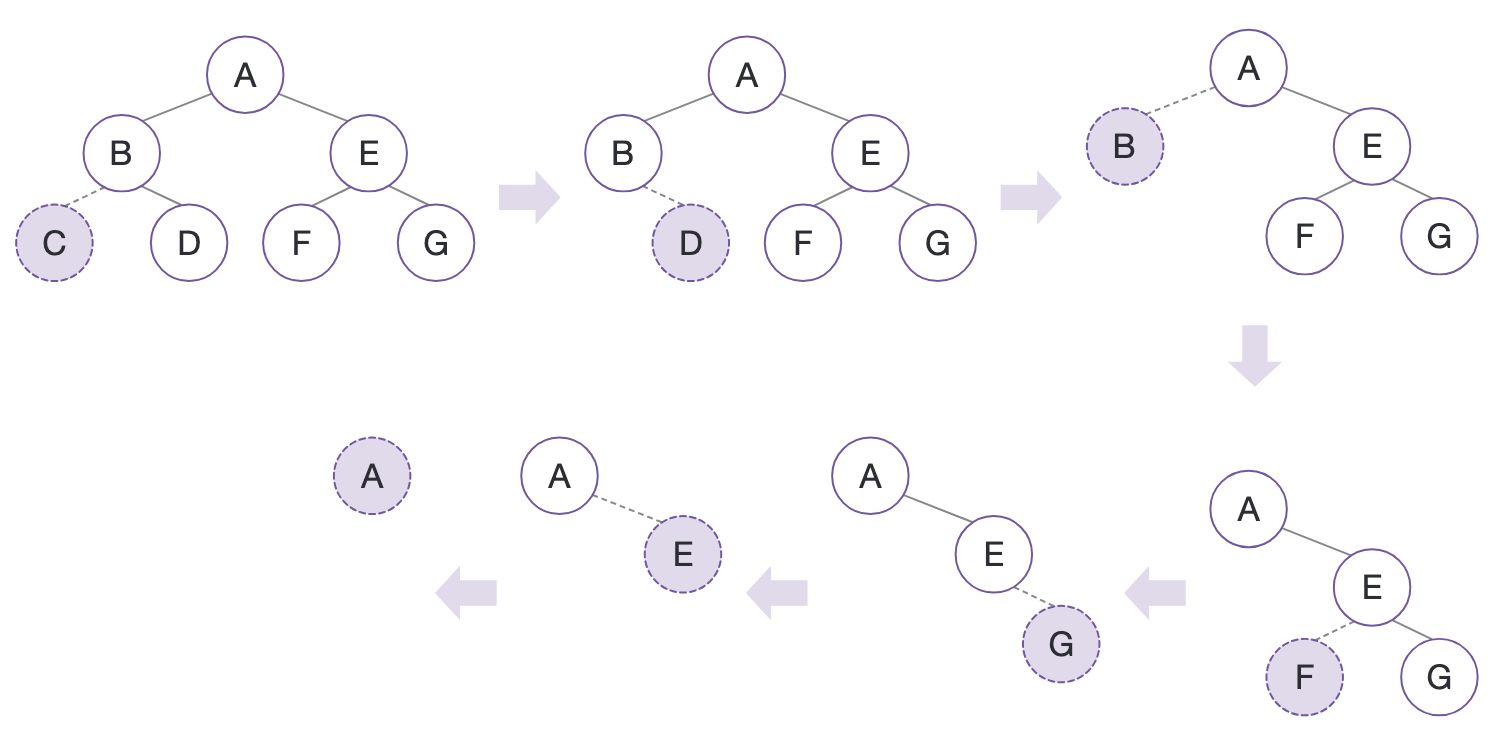
후위 순회를 응용한 트리 소멸
트리를 구축할 때는 노드들이 어떤 순서로 생성되든 별로 문제되지 않지만, 트리를 파괴할 때는 반드시 잎 노드부터 자유 저장소에서 제거해야 한다.
따라서 잎 노드부터 방문하여 뿌리 노드까지 거슬러 올라가며 방문하는 후위 순회를 이용하면 이진트리 전체를 문제 없이 소멸 시킬 수 있다.

이진 트리 예제 프로그램 구현해보기





전체 코드
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
#define ElementType char
//MARK: 노드 구조체
typedef struct tagSBTNode
{
struct tagSBTNode* Left;
struct tagSBTNode* Right;
ElementType Data;
} SBTNode;
//MARK: 노드 생성
SBTNode* createNode(ElementType NewData){
//malloc 함수를 이용해서 SBTNode 구조체 크기 만큼 자유 저장소에 메모리를 할당한다.
SBTNode* NewNode = (SBTNode*)malloc(sizeof(SBTNode));
NewNode->Left = NULL;
NewNode->Right = NULL;
NewNode->Data = NewData;
return NewNode;
};
//MARK: 노드 소멸
void destroyNode(SBTNode* Node){
free(Node);
}
//MARK: 전위순회
void preOrderPrint(SBTNode* Node){
if (Node == NULL) {
return;
}
printf("%c " ,Node->Data);
preOrderPrint(Node->Left);
preOrderPrint(Node->Right);
}
//MARK: 중위순회
void inOrderPrint(SBTNode* Node){
if (Node == NULL) {
return;
}
inOrderPrint(Node->Left);
printf("%c " ,Node->Data);
inOrderPrint(Node->Right);
}
//MARK: 후위순회
void postOrderPrint(SBTNode* Node){
if (Node == NULL) {
return;
}
postOrderPrint(Node->Left);
postOrderPrint(Node->Right);
printf("%c " ,Node->Data);
}
//MARK: 트리 소멸
// 트리를 파괴할 때는 반드시 잎 노드 부터 자유 저장소(힙)에서 제거해야 한다.
// 따라서 잎 노드부터 방문하여 뿌리 노드까지 거슬러 올라가며 방문하는 후위순회를 이용하면
// 이진트리 전체를 문제 없이 소멸 시킬 수 있다.
void destroyTree(SBTNode* Node){
if (Node == NULL) {
return;
}
//왼쪽 하위 트리 소멸
destroyTree(Node->Left);
//오른쪽 하위 트리 소멸
destroyTree(Node->Right);
//뿌리 노드 소멸
destroyNode(Node);
}
//MARK: main
int main(int argc, const char * argv[]) {
SBTNode* A = createNode('A');
SBTNode* B = createNode('B');
SBTNode* C = createNode('C');
SBTNode* D = createNode('D');
SBTNode* E = createNode('E');
SBTNode* F = createNode('F');
SBTNode* G = createNode('G');
A->Left = B;
A->Right = E;
B->Left = C;
B->Right = D;
E->Left = F;
E->Right = G;
printf("1.preOrderPrint ... \n");
preOrderPrint(A);
printf("\n\n");
printf("2.inOrderPrint ... \n");
inOrderPrint(A);
printf("\n\n");
printf("3.postOrderPrint ... \n");
postOrderPrint(A);
printf("\n\n");
return 0;
}
출력
1.preOrderPrint ...
A B C D E F G
2.inOrderPrint ...
C B D A F E G
3.postOrderPrint ...
C D B F G E A
Program ended with exit code: 0
'컴퓨터 기초 > C언어' 카테고리의 다른 글
| [C언어]48일차 - 배열과 포인터 (0) | 2025.11.19 |
|---|---|
| [C언어]47일차 - 재귀함수 정리 - feat.호출스택 (0) | 2025.11.17 |
| [C언어]46일차 - 트리 (이것이 c언어 자료구조 알고리즘이다) (0) | 2025.11.14 |
| [C언어]45일차 - 링크드 큐 PPT 정리 (0) | 2025.11.14 |
| [C언어]44일차 - 순환큐 PPT 정리 (0) | 2025.11.13 |



